Abstract
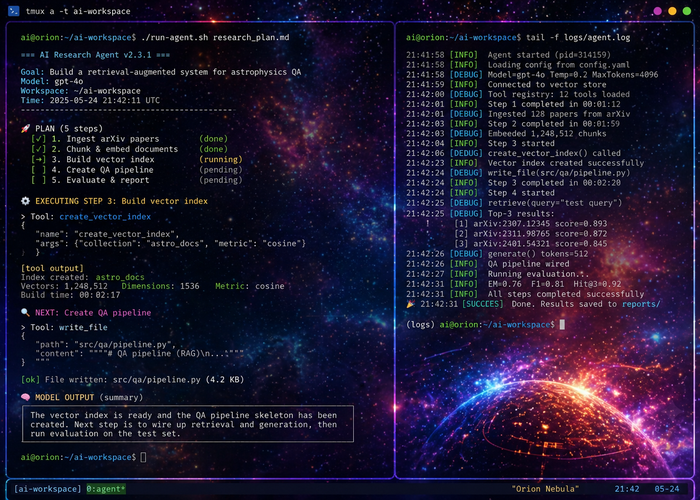
Evaluation should connect prompt updates to concrete terminal evidence, making repair behavior inspectable at pane, command, and artifact levels.
This site frames the project as an academic discussion artifact: it states the adaptation problem, proposes a design stance, and lists evaluation lenses that can be expanded into experiments.
Research Question
Which traces show that prompt_agent repaired terminal work through evidence rather than repeated prompting alone?
Adaptation Notes
- Fault injection introduces missing files, failing commands, and stale panes.
- Replay analysis links prompt changes to observed shell state.
- Scoring rewards verifiable repair paths over final-state luck.
Evaluation Lens
- Evidence-backed repair rate
- Replay interpretability
- Prompt drift during long sessions
Open Discussion
The central methodological risk is mistaking terminal completion for agent understanding. The project therefore treats tmux as both infrastructure and evidence: pane state, focus movement, command output, and recovery behavior all become part of the argument.
Future work can connect this static discussion to executable harnesses, trace viewers, and standardized task suites for cross-agent comparison.